
Turning unreadable text into evidence
Chatbots come to the rescue once again


You know that feeling when you're staring at a crucial piece of evidence - a blurry license plate, a pixelated document with names you can't make out, or a grainy screenshot where you know the information you need is right there, taunting you from behind a wall of pixels?
You don't? Lucky you. I encounter this problem constantly in my investigations - whether it's extracting names from footage, decoding partial numbers from social media posts, or reading distorted text in documents. While everyone else is out there living their lives, I'm playing "Guess That Pixel". I don’t mind. The ability to transform the unreadable into readable intelligence is awesome.
Time for a manual on making blurry nonsense make sense. The tools and techniques in this article aren't theoretical. They're practical methods you can apply to your own difficult-to-read evidence. Because in OSINT, the difference between a dead end and a breakthrough often comes down to making those last few pixels count.
The real work happens between your ears and behind your eyes - knowing which tools to combine, how to verify outputs, and when to trust (or distrust) your results. Because at the end of the day, the difference between amateur hour and professional investigation is having a system that consistently works, even when the pixels are fighting back.
The blurred license plate
People in open source intelligence love their tools. Ask any specialist for recommendations and they'll fire off names like "just use Topaz Gigapixel Pro" or "try any Gyro-based Neural Single Image Deblurring tool - here is a list of all these tools. But the real solution isn't always in your favorite software; it's often about admitting you don't know everything.
I showed this blurred license plate to 50 people from BBC Verify during a session in London. Most of them could easily name 3 tools that would help deblur it. But here's the thing - they all didn't work. What are your options now?

My favorite technique in 2025: I put all my failed attempts into an AI chatbot like some kind of digital therapy session - "I tried Topaz, Remini, DeblurGAN v2, ImageJ+ DeconvolutionLab2" - and then watch as it suggests "BeFunky Image Editor." Seriously? I'd never heard of BeFunky before, but it turns out this free tool with a name that sounds like a rejected Netflix original actually worked better in this case than the $200 fancy software. It's peak "maybe I don't know everything" energy, and honestly, that's when the real breakthroughs happen:

That tool never worked that well again, but hey - when I listed it among the tools I'd already tried, I got fresh suggestions. Sometimes the best advice comes from sharing your failures.
When you actually can read the text, you need to find context. While researching a red Chevrolet Camaro's license plate (used by a Dutch criminal), I didn't have trouble reading the digits - my problem was with reverse image searching. Sometimes Google simply doesn't recognize a cropped detail of a photo.

You can work around this by typing the visible text into Google Images instead of reverse searching the photo itself. This led me to images of tourists in Iran driving the same red Chevrolet Camaro with the same license plate. Ah, the criminal had rented a car. (full story here).


The open laptop
Here's a pro tip that sounds almost too stupid to work: If your text isn't completely potato-quality, just literally ask AI to transcribe it directly. No fancy tools, no image processing wizardry - just upload the thing and say "what does this say?" My current favorite is Gemini Pro 2.5, which apparently has decided to become the world's most overqualified proofreader.
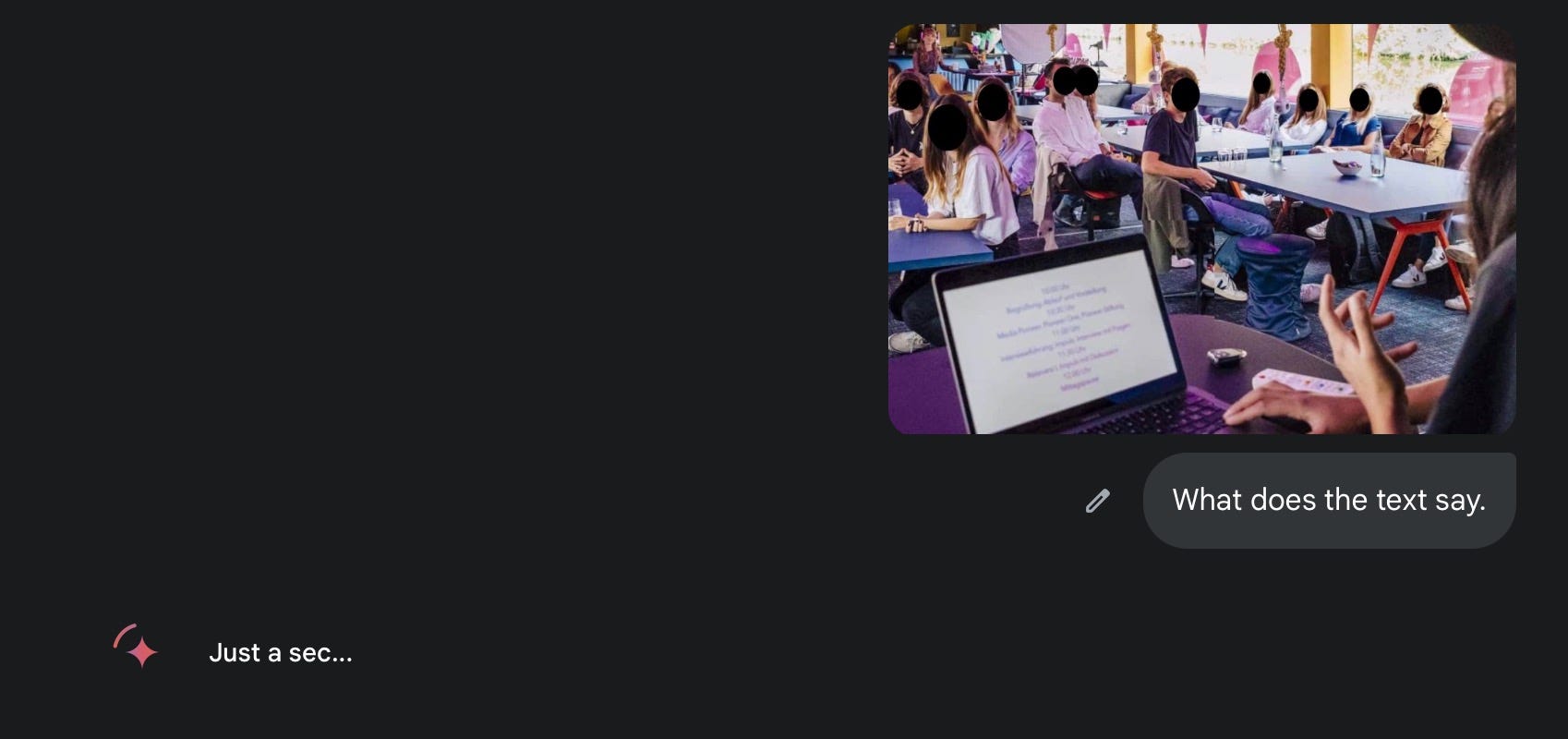
While you're still squinting to figure out if that's an 'a' or a sad face, the chatbot has already transcribed AND translated the unreadable text for you:

The 170 unreadable words
Take a look at this photo. I travel a lot, so I can't lug monitors around with me. Instead, I use virtual reality glasses to get work done. How many words can you make out in this screenshot that I intentionally blurred as much as possible?
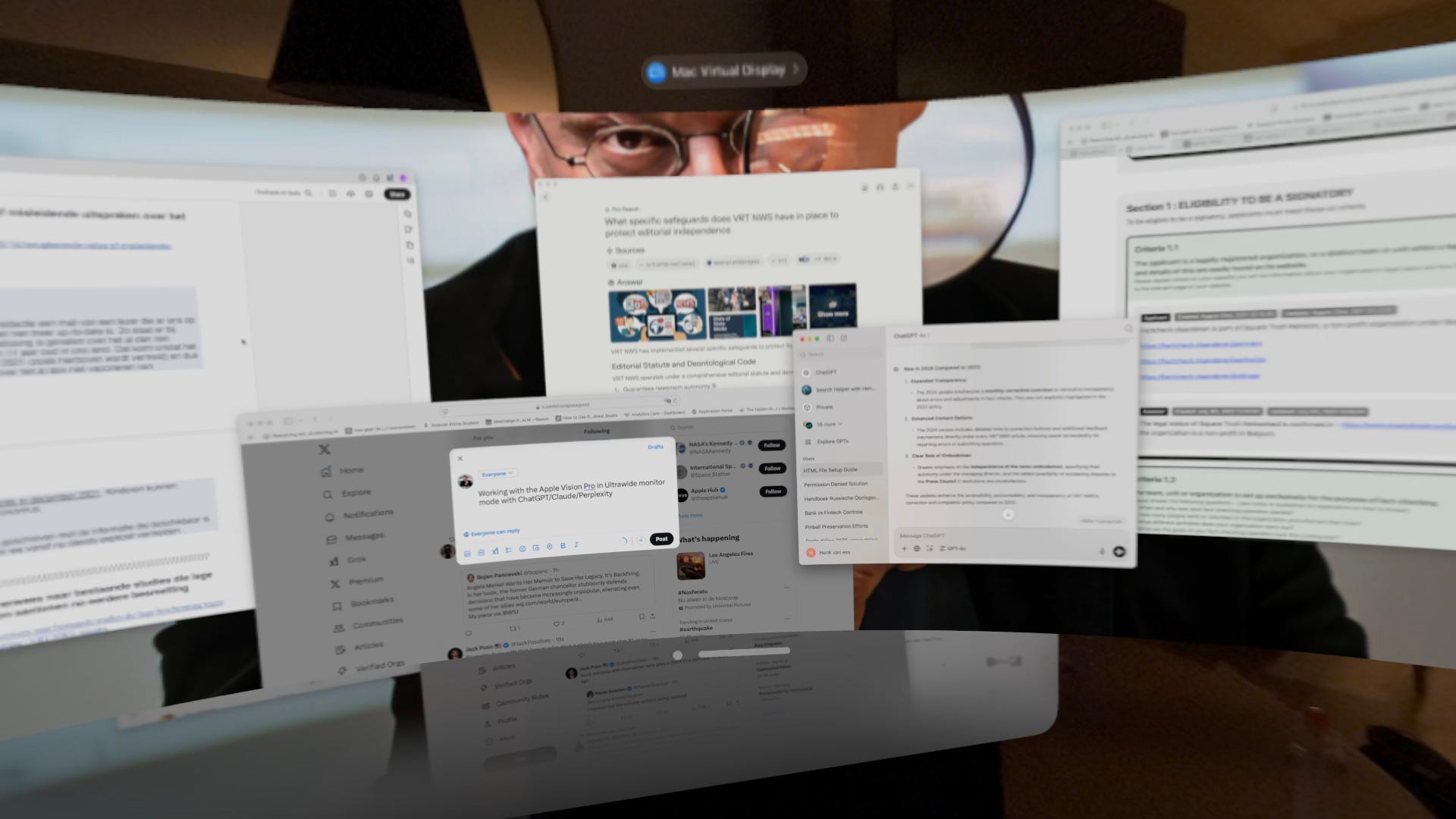
While you're still squinting at the image, I uploaded it to Gemini 2.5 Pro. It managed to read about 170 words from the photo and gave me an accurate summary of what I was actually doing.

Geolocation with text
I'm currently working two weeks in Berlin, and I love giving these little OSINT intro sessions to students how terrifyingly effective investigative techniques can be. It's educational, it's slightly horrifying, and it definitely makes everyone immediately check their privacy settings.
Let’s dissect this photo. The question is : where is this, and when?

The "no bikes" sign probably rules out Malta, Cyprus, Spain, Luxembourg and UK and makes Netherlands, Denmark and Finland highly likely candidates.
The reason is simple: "no bikes" signs are most common in countries where cycling is actually a thing. These signs probably don't exist where nobody bikes in the first place - they exist where so many people bike that you need to actively tell them not to park here. It's like finding "no swimming" signs at the beach versus finding one in the middle of the Sahara Desert - one is practical public safety, the other is just a mirage.
You can see text appearing twice - a word that says "essen" or ends with "Essen" - plus a greenish logo with three, four words. This time, AI doesn’t outsmart us:
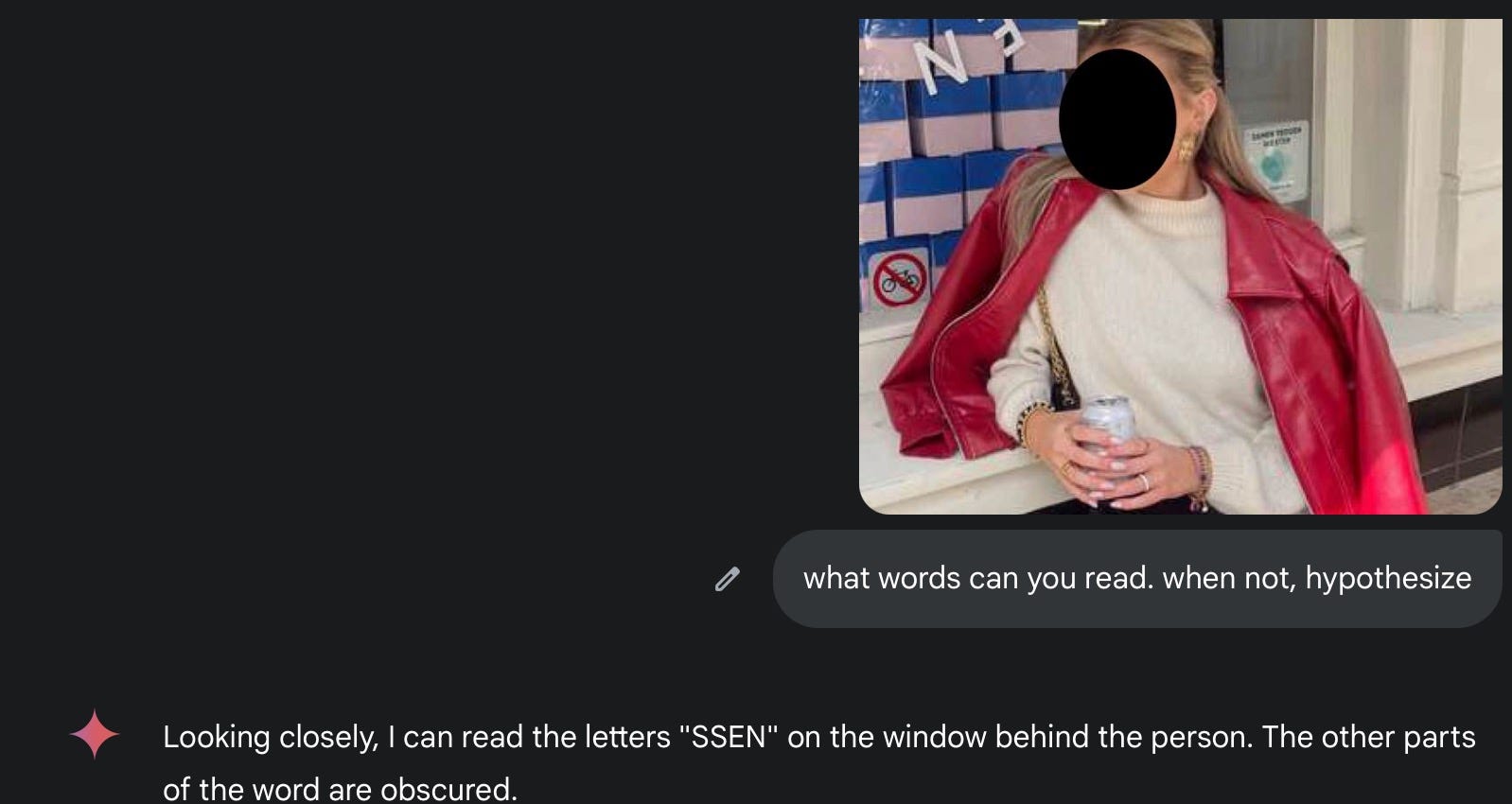
Can BeFunky come to the rescue once more? It improved the text quality enough that I could read the words "samen redden" . This means the text is in Dutch and says "samen redden [something]" - which translates to "save together [something]."

So what's worth saving? It's probably a sticker on a window of a shop or restaurant, so it probably won't say "Save together... communism." Maybe it says "Save together capitalism"?
Nah, scratch that - that's way too far-fetched. It's probably something uplifting like "Save together... energy" or "Save together... the whales" or just "Save together... on parking." Or maybe... wait, no, I'm doing that thing again where I overthink everything. Don't think. Stop guessing. Start searching.
We're pretty sure "save together" is followed by one or two more words - probably not more than 7 characters if the font size matches the first line. Now here's the fun part: how exactly do you explain this incredibly specific font-analysis-based word count estimate to Google without sounding like a conspiracy theorist who's had way too much coffee? This is the point where normal search queries meet forensic typography (which we will discuss in part 2 of this article), and everyone starts questioning your life choices.
How do you tell Google that you don't know the right words?
